forensic-analysis
Researched and written by Carolyn Holzman, forensic SEO
Published March 1, 2026
It’s Not Just Listicles. Its Not Use of Scaled AI Content – Its A Real Problem
Why? The same patterns affecting listicles are baked into how many sites and even Google itself structure their content.
Listicles And The Great Decline of February 2026
February 2026 has yielded a number of articles concerning the possible targeting by Google of a particular article format; the listicle. In truth, there were really only two articles that provided original analysis. The first was from Amsive’s VP of SEO Strategy & Research, Lily Ray, her observations detailed in Google Finally Cracking Down on Self-Promotional Listicles? And Clearscope.io founder, Bernard Huang’s Bad News: It’s Not Just Listicles. Everything else afterwards appears to be secondary sources and commentary.
In Lily’s article, the connection was made between an undeniable decline in visibility of the sites as evidence of a specific crackdown on this format. Google is now devaluing this specific pattern of self‑promotional, templated listicles that look like they were produced to exploit SERP and AI‑answer behavior.
Bernard’s article starts from the “Google is deprioritizing self‑promotional listicles” theory and then shows data suggesting the impact is broader than a single format. It attributes much of the volatility to structural changes in search, especially Gemini 3 becoming the default model for AI Overviews, which can synthesize comparisons and satisfy best queries directly.
As a forensic SEO and tester, this situation interests me.
There is no denying that something has and is still happening. From all sides, the conclusions diverge on exactly why. The only consensus is that whatever it is, the reason lies at our feet and if we have a decline we’re doing it wrong.
But are we?
Can This Decline Be Explained By Anything Else
Could there be another plausible and perhaps more likely explanation?
Short answer. Yes.
As one of the original testers working with single variable html testing, one of the most challenging aspects of testing is uncovering unaccounted for factors and even any assumptions that we bring to any analysis. Things that we assume could not possibly be a factor are often the most fertile ground for increased learning.
Whether it was a listicle or not there were visibility declines
In the spirit of a friendly stress test of the conclusions drawn, I decided to look at many of the same sites used as the basis for Lily’s case study and Clearscope itself. Using Sistrix as well, I looked at over 110 page URLs, a few listicles but overall content with Table of Contents links covering the same range of sites and confirmed that each was involved in the overall downward trend of visibility.
I viewed individual pages involved and with the exception of one site identified from Ray’s original case study, found on each page a potential alternate explanation.
In those cases, every page, without fail, contained either Table of Content html in the body of the article, in a sidebar widget and in one case, a site where on each page TOC appeared in both the article AND the sidebar.
It was not limited to self-serving listicles. All sites reviewed were riddled with table of contents.
Arrived at Different Conclusion as to Cause of Visibility Decline
Observations reveal a profound impact on a wider range of article styles, not just self-serving listicles.
While we have reached new territory with AI in terms of how search is satisfied, two things can be present and not be related. Specifically, sites can be scaling AI written content AND experience a decline without one causing the other.
Given the fact that these declines appear to impact sites NOT scaling AI written content, another possible culprit appears to be in play which can explain the common experience for both those scaling and those not scaling AI written content.
The Canonical As A Suggestion Leads to Unintentional Duplicate Content
What we are seeing could also be triggered by a system in which the canonical is now a suggestion.
If we game out what would happen if same-page jump links even where a rel=canonical tag is present become treated as individual pages and no longer attributed to the main web page canonical, THIS is what that would look like:
Duplicate content everywhere getting suppressed either with a smaller and smaller query footprint until, in some cases, the page is completely washed out of the live index.
To see this we need to step backwards.
Parameters Create What Appear To Be New URLS Says Google
Tracing the deprecation of the Google URL Parameter Tool from April 2022, you don’t have to squint too hard to see it.
In 4 years we’ve gone from Google assuring us that Google’s crawlers will learn how to deal with URL parameters automatically to this year Google’s Crawl Team filing bugs Against WordPress plugins saying that the problem with “parameters is that each one creates what appears to be a new URL by adding text”.
While mainly confronting ecommerce plugins as the source of creating these new URLS - they say, “The crawl waste is often baked into the plugin layer. That creates a real bind for websites with ecommerce plugins. Your crawl problems may not be your fault, but they’re still your responsibility to manage.”
This Mountain in the Data Phenomenon Impacts Google itself
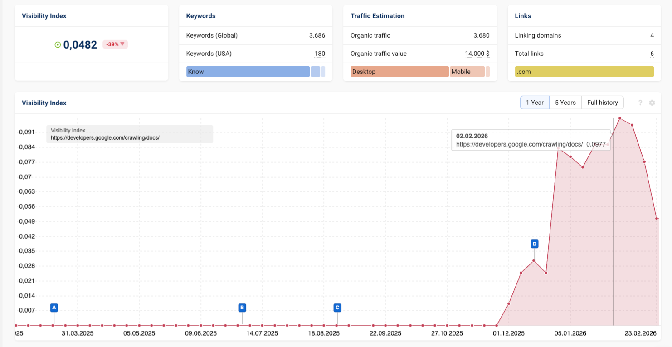
This is the Sistrix Visibility tool isolating Google.com by a directory. https://developers.google.com/crawling/docs/*
D = December 2025 Core Update
Precipitous drop dated February 2, 2026
This also aligned with the dates in early February in Ray’s “The Google Crackdown of Listicles” examples.
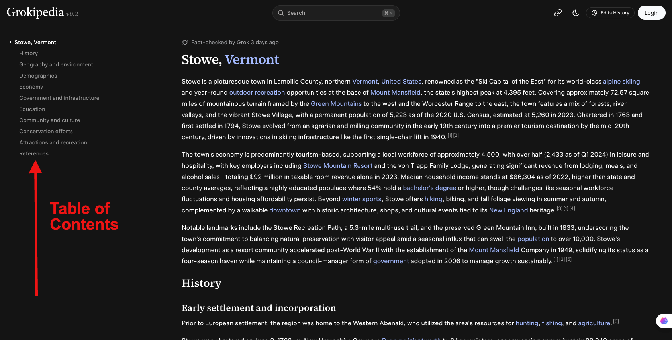
Page Example of Google Developer Docs to illustrate use of TOC
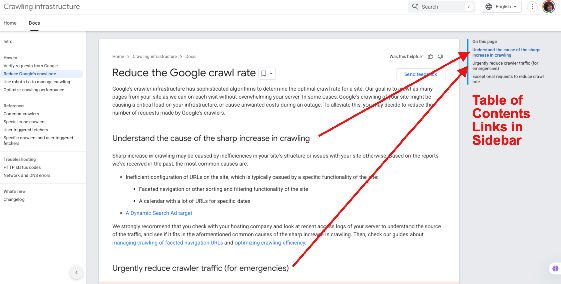
https://developers.google.com/crawling/docs/crawlers-fetchers/reduce-crawl-rate#understand-the-cause-of-the-sharp-increase-in-crawling
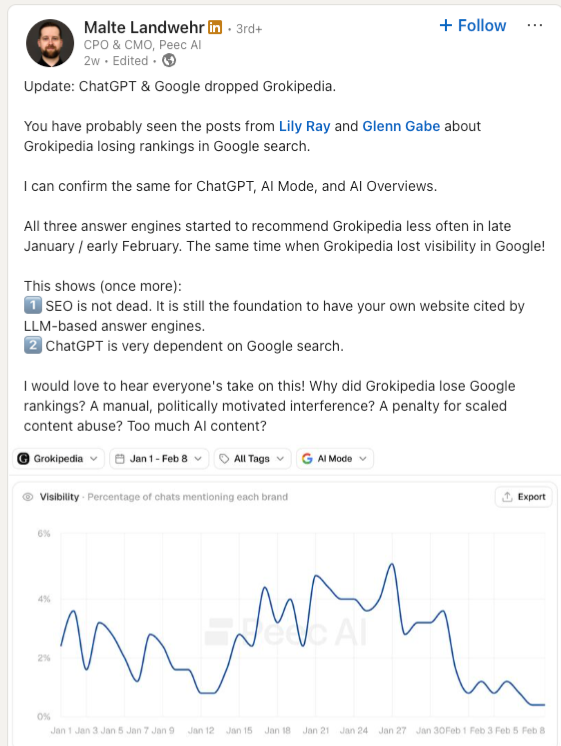
While We’re At It - Grokipedia.com Another Big User of TOC
Recently, Malte Landwehr confirmed that Grokipedia was no longer cited by ChatGPT. Turns out it’s not even in Google very much these days.
 .
.
Sistrix domain data for Grokipedia.com. Also illustrates a deep drop on the same day 2/2/26.
Sample page on Grokipedia.com.
Data Reveals Growing Claims of Scaled Use of Automated AI Content is Killing Sites Are Unfounded
Over the past week as I was collecting and comparing data for this report, increasingly new reports emerged from respectable sources claiming sites using automated AI generated content are responsible for their own destruction in visibility.
Explaining “How AI content sites lose visibility” - a familiar experience is described. Short term surge in traffic, gaining traction only to “see substantial declines” later and in this most recent episode a large number of enterprise sites in early February experienced the deep decline.
Grokipedia is used as such an example. And yet, there is another possible and reasonable explanation standing by.
Does The General Consensus of an AI Penalty Hold When Even Google Appears To Have Been Hit
Are we going to respond to Google with the same observations that are commonly said to other content creators when they get hit?
The same thing that happened to Grokipedia is actively happening to Google’s visibility. Same pattern. Same timeframe.
If both Google and Grokipedia experience a similar “bloom” of impressions followed by drastic declines, if no one is accusing Google of recklessly scaling AI content creation, then how can we point our fingers at Grokipedia? Or Shopify? Or Elementor? Or UpClick? Or DataFeedWatch? Or UserPilot?
If Google experiences the same, does that mean Google needs to work on its SEO and stop exploiting its content just to be cited in AI responses? Does this also mean that Google is putting out content that doesn’t provide value?
Why Suspect Table of Contents HTML
While I share a few of the BIG ones, this loss of visibility is nothing new, at least since the appearance of the Helpful Content System in 2022.
The new part is we’re just now seeing how this has been impacting some of the largest enterprises over time.
As early as 2023, I could see it in the sites I was working on. Mostly the type of sites I was looking at were affilliate sites. They were the ones who initially experienced the most dramatic of Helpful Content hits. Table of Contents format is a staple of that type of site.
It is new for me to see that Helpful Content is impacting even Google. I was very surprised. Apparently, even Google isn’t immune from its own system.
They have the same increase in their impressions followed eventually by a sharp drop. Go back far enough and there’s a mountain shape in the data.
Since 2023, each time I’ve had a site to diagnose either a paid project or through a comment on social media that I followed up on and was given even just access to the domain name, the presence of table of content html was noted.
Given the parameter issues in which Google says they can appear like individual pages and that TOC links are a subset of parameters with the #anchor texts, it feels like a lot more than just smoke.
The Clues are in the Code
The html in the source remains the same whether we call them listicles or page content links - a list of content summary is hyperlinked to the header tags which when clicked from the list causes a jump down to that section of the page.
Each of the jump links (fragment links, anchor links etc) is formed by adding to the slug of the page a single hashtag symbol. Below is an example. Listicle links could be considered a specialized type of Table of Contents because of the use of the html element list, <li>.
They look something like this:
<li><a href=”#keyword-or-number-here”>Shirts</a></li>
The same intention and function is also in this expression of a sidebar widget.
<a href=”#02”>What products are trending right now?</a>
Are These Really Links
One of these is an internal link and one of these is the type of link in the Listicle/TOC.
<a href=”/inner-page-link”>keyword here</a>
<a href=”#02”>What products are trending right now?</a>
HyperText Markup Language (HTML) that we use every day is the foundational language used to create and structure the content of web pages. We use tags to organize text, images, and multimedia into elements like headings, paragraphs, and links, acting as the skeleton for web browsers to interpret and display.
‘A’ Tags Are HTML That Scream to Crawlers Come Get Me!
The <a></a> html tags are the fundamental building blocks of web navigation for crawler bots like Googlebot.
The href attribute in an <a> tag tells the bot that another URL exists, prompting a crawler to add that page to its queue for crawling. The target URL designated by the href can be absolute https://www.domain.com/page-one/ or relative ( /page-one).
These html instructions are fundamental to web navigation.
We have no evidence that any crawling system can distinguish between a link to another page or domain and a jump link on a page that jumps to itself.
Anything After The Trailing Slash Counts
This is what a google crawling system fetcher sees when it hits TOC/Listicles. Links. Links. And more links.
https://domain.com/#01Jumplink
https://domain.com/#02Jumplink
https://domain.com/#03Jumplink
https://domain.com/#04Jumplink
Each one of these can be treated as a separate URL that leads to the same page of content.
Same holds for any parameterized urls, if they are found by a Google search bot, they are crawled.
In 2023, several URL parameters, particularly on Shopify and other e-commerce platforms, have been frequently indexed by Google, leading to duplicate content, crawl budget depletion, and, in some cases, a potential bug with the ?srsltid.
The Canonical Tag Handles This…Not
As noted earlier, events and evidence do NOT support this assumption once Google deprecated the parameter tool in Search Console April 2022.
Duplicate Content Implications When Hitting the Helpful Content System
Starting in 2024 and now being seen in enterprise sites, I’ve observed various search console datasets for sites that showed an increase of impressions without increase in clicks.
If I didn’t know better, I’d say that Google began treating these jump link URLs separately from the canonical URL once the Helpful Content Classifier went into full swing.
And even Google has said maybe we shouldn’t be using Table of Contents in our content.
At a closed door summit event a Google Creator Summit in Washington, DC in September 2025, one of the participants shared:
### **Your Table of Contents Might Be Hurting You**
Google shared that some Table of Contents widgets can confuse their crawlers and even reduce clarity scores.
Treating TOC as separate duplicate pages could also be described more precisely as reduced clarity scores.
(un)Helpful Content Implications
Previously I had considered that IF Google was treating these #anchor links as separate pages and generating duplicate content issues, it had to be a broken canonical system.
It became clear and undeniable that there is correlation between the presence of Table of Content features and the slow reduction in visibility of those pages and then with enough of those pages, the entire site.
Duplicate content within the same domain would be obvious in a system where AI-guided topical assessments such as what Helpful Content performs a horizontal content analysis. Google no longer judges a single page in isolation but now also against other pages on the site to form a score for siteFocus and siteRadius which we gleaned from the leak of a document containing Google’s api content warehouse in May 2024, two weeks after I published my findings.
The timing of the new ability for Google to perform such an analysis was felt most dramatically during the Sept 2023 standalone Helpful Content Update. All those HC rules and systems were rolled into the Core Algorithm by March 2024.
Could Helpful Content Be Working like an AI-guided Topical Measurement
It would appear so.
In the absence of direct confirmation from Google, we can look at actual SERP behavior of a collection of URLS, such as those in Lily Ray’s case study and Bernard Huang’s assessment of Clearscope’s site.
In each case but one, the presence of the listicle (or TOC) links revealed the same jump in visibility (more impressions) prior to the roll out of Helpful Content.
When this response is viewed through the Search console it appears as a “bloom of impressions without any increase in clicks” as detailed in a Moz article I wrote last year.
“In the past 2 years, I reviewed close to fifty sites without access to Search Console data. In each case, they showed a bloom of visibility (impressions) before a significant reduction in the number of ranking queries that dropped the positions of their canonical pages during and after the updates.”
To illustrate this with one of the sample sites from Ray’s original case study, below is a screenshot of the visibility of an interesting webpage on it.
I tracked its content alterations loosely by viewing a dozen url snapshots over the past 4 years.
Published on April 22, 2022, table of contents appears to have been added to the article (archive.org) several months after it was published and the upward trajectory from that time is undeniable.
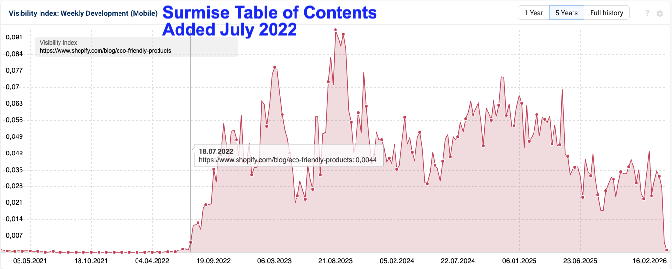
Likewise, the recent deep drop in visibility is equally undeniable in early February 2026.
Decline Impacts pages With TOC Even If The Page Is Still Findable In SERPS For Some Queries
How can that be?
There seems to be a price to be paid by the duplicate content Google’s HC perceives. I can not stress enough that the duplicate content is not a true condition of the site. It’s just a false narrative courtesy of the HC system using the DNA of our html.
Additionally, all those duplicate pages focused on different, varying grouping of related queries related to their associated header structure. Those expanded queries based on the headers was most likely the mechanism that powered the subsequent increase in impressions. This appears in analysis tools as increased visibility.
The canonical page competes with each of the TOC generated URLs which are behaving like separate pages.
(Ironically, there’s a page on an enterprise SEO software site about cannibalized pages that is cannibalized in the data. Oh, and it contains TOC links on the page as well.) Image below.
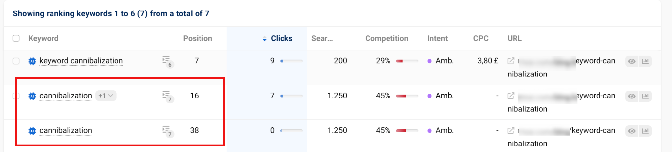
When TOC generated pages appear to be tagged as unhelpful content, they begin to slowly disappear from the data.
All the extra queries which were driving the jump in impressions in data begin to not longer perform.
The decline in visibility can be alternately expressed as when the number of queries attached to a page condenses. The page could be findable, maybe even on page 1. For enterprise sites they could still by virture of their size be somewhere on page 1, for smaller sites the reduction can, and as it did for many, result in a catastrophic loss of revenue to the business.
What Could Have Altered To Create Drops in Visibility For So Many Sites at One Time in February 2026
Based on this information compared to the drop of performance and WHEN they experienced that drop, I suspect that Google has ALWAYS been able to see these jump links. The December 2025 Core update likely was ‘set’ to a lower tolerance level for unhelpful content.
This ability to adjust tolerance levels algoritmically could also provide context for why in the beginning of this monumental shift in 2023 we saw some content using TOC/Listicle links disappeared while other (mostly enterprise) sites used them with seemingly impunity.
Post the December 2025 Core Update, with an adjusted the tolerance level for domains (including themselves apparently) which reflected massive amounts of duplicate content, the adjustments have been felt SERP-wide afterwards.
Where Conclusions Meet and Where They Diverge In How To Avoid This Result Moving Forward
I have no doubt that part of this Perfect Storm includes AI discernment but not as has been suggested by identifying and penalizing a selective content quality being used to exploit SERP and AI‑answer behavior assessment.
What we witnessed was an identification of artificial duplicate content in sufficient quantity on domains as a result of the multiplying effect of HC assessed parametered URLs. In short, it was a helpful content hit.
There are many individual pages which are not “listicles” that suffered visibility declines. e.g. Google’s developer document directory, Grokipedia, Ahrefs blog etc. The enterprise sites that contain MORE of these TOC/Listicle links on more of their pages, according to visibility data, have been seeing this loss of visibility for a longer period time than just the beginning of February but were at a loss to explain it.
AI produced content being a new factor in consideration and like most new tools used recklessly seems to be the likely culprit until you see the slow declines over time.
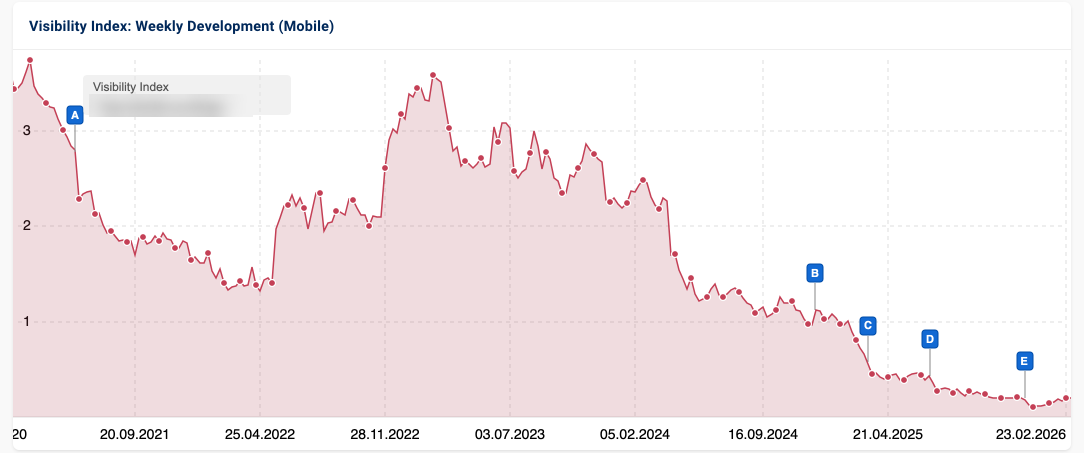
This is the past year visibility for the blog section of an enterprise site that is recognized for NOT abusing AI created content. It’s getting challenging for the logic to hold that the presence of a decline like this in visibility is the confirmational signal of abusing the use of AI generated content.
In the case above, the TOC links in their blog content were used for general content purposes.
New domains of new enterprise businesses which have started up in recent months are publishing articles claiming “The AI Did It To These Other Sites” while using TOC links themselves. I regret having to say that if the use of TOC continues, it is only a matter of time before they will experience the rise and fall in their own visibility once their domains have acquired a HC classification.
A Classic Helpful Content Response
I published an analysis paper (paid) in Spring of 2024 which details how I arrived at the conclusion that Helpful Content System is topical in nature and classifies domains by measuring the semantic meaning of all pages as a collection in relation to each other.
But other than identify that behavior, I could not find an SEO tool that could cost-effectively run a horizontal analysis on existing content.
I have now. And full disclosure I’m a partner in VizzEx and shaping it with my understanding of what HC measures. There is a wordpress plugin and a HubSpot application for VizzEx and plans for more platforms.
Are Listicles and Pages with TOC Links Doomed?
The love affair with listicles begins and ends because of how often articles WITH TOC/listicle links are seen cited in AI.
An exciting aspect which I understand from testing this, the reason AI cites them is NOT because of the TOC html.
The reason they are cited is the H2s which are used to set up the jump are part of the semantic html. H2s send a topical message.
AI would cite content with just the H2s alone! The header structures are what makes it easy for LLMs to spend the tokens on your content.
In fact, my indexation testing data indicates that Google is LESS likely to index content that isn’t set up with header structures LIKE what you see in what we call listicles. They also aren’t going to spend the resources on a wall of content. And if Google doesn’t have that content in their index, there goes all the potential LLM citations.
Should Anyone Write Listicles
Now whether you do listicles using TOC links or not is your business, literally. There may be reasons to do them.
But doing them solely to get cited is starting your domain down a path where Grokipedia and even Google find themselves.
What February 2026 Revealed To Us
Your authority won’t save you. Writing them as a human won’t save you.
If you use TOC in its current form and flood your domain with them to ensure you get cited in LLMs or even just out of habit, you will experience a short term gain.
But then you will pay the piper when your content is slowly or suddenly squeezed out of Google’s index because the HC or rather UN-helpful content tag is on the accidental duplicate content they create.
All indications point towards Google’s index as the source of many LLMs, specifically ChatGPT. So eventually your content because it gets pushed out of Google’s index, can’t get cited by those LLMs that use it.
Grokipedia is the ultimate cautionary tale. (Just not the way some portrary it to be.)
A Broken Canonical Attribution System
I used to think and talk about this phenomenon as being a broken attribution system.
I no longer think it’s broken by accident. Within the HC system, it behaves as a feature, not a fault. Google’s crawling system may function within the system, but their HD classifier does not appear to do the same.
At the heart of this, the problem is what is hurting us lies within the DNA of how the web works when our content is being classified by a Helpful Content System that assesses without consideration of the canonical for same page links.
This won’t be the last time I write about this because I think it’s going to take a while for all of us to come to grips with this unimagined reality.
As I see it, the danger comes from two directions.
On the one end, a trusted and beloved content feature: the table of contents.
On the other, (un)Helpful Content, which to many is still a black box.
Our assumptions about each combine together to form a toxic cocktail.
Deep beliefs that TOC could not possibly behave differently than it has historically coupled with a literal interpretation of Helpful Content has brought havoc to the SERPs and small businesses in the early days of HCS. Now the loss is spread more evenly when its affects all of us, including Google itself.
Are Listicles That Good Or Should We Toss Them
Truthfully, we do NOT yet know the real nature of listicles in SERPS because the game is tilted. We can’t separate out what the true SERP effects are because within its very html structure there is an element that brings a predictable short term thrill followed by long term pain.
I wonder what might happen if if we let the semantic HTML of the headers do the talking.
Perhaps content structure using headers without these TOC links will continue to be cited by LLMs without risking a false classification of duplicate content by the Helpful Content System.
Being able to identify the mechanism responsible for the site content of any business size getting squeezed out of search results is useful.
Recognizing a system designed to insist that the canonical is just a suggestion on anything is our first progressive step to stem the tide.
More to come.
####################################################
You can follow/find me on Linkedin.
You can email using my first name @vizzex.ai
Go here to be first notified of the Really Helpful Listicle wordpress plugin
Catch every episode of Confessions of An SEO wherever you get podcasts.
P.S. For those like myself who can’t help themselves from checking everything, the irony is NOT lost on me that Github has #anchors baked into its system. Not my choice, but my responsibility, right Google? Hmmm, maybe this page is my next test!